Questa pagina è usata come repository per quanto riguarda oggetti all’interno di Kubernetes e la relativa command line interface con i comandi usati più comunemente. (non vuole essere una guida esaustiva su Kubernetes ma vuole essere più un repository di note e comandi più comunemente usati)
Containers?
I containers sono un tecnologia che raggruppa il codice e i requisiti necessari ad un applicazione per potere funzionare.
– portabiliti
– meno uso delle risorse compute
– rapidità nella messa in servizio
– capacità di scalare orizzontalmente usando le replicas
Cosa è Kubernetes?
Kubernetes (talvolta abbreviato in K8s, con l’8 che indica il numero di lettere tra la “K” e la “s”) è un sistema open source per eseguire il deployment, scalare e gestire applicazioni containerizzate ovunque.
(https://cloud.google.com/learn/what-is-kubernetes?hl=it)
Kubernetes CLI
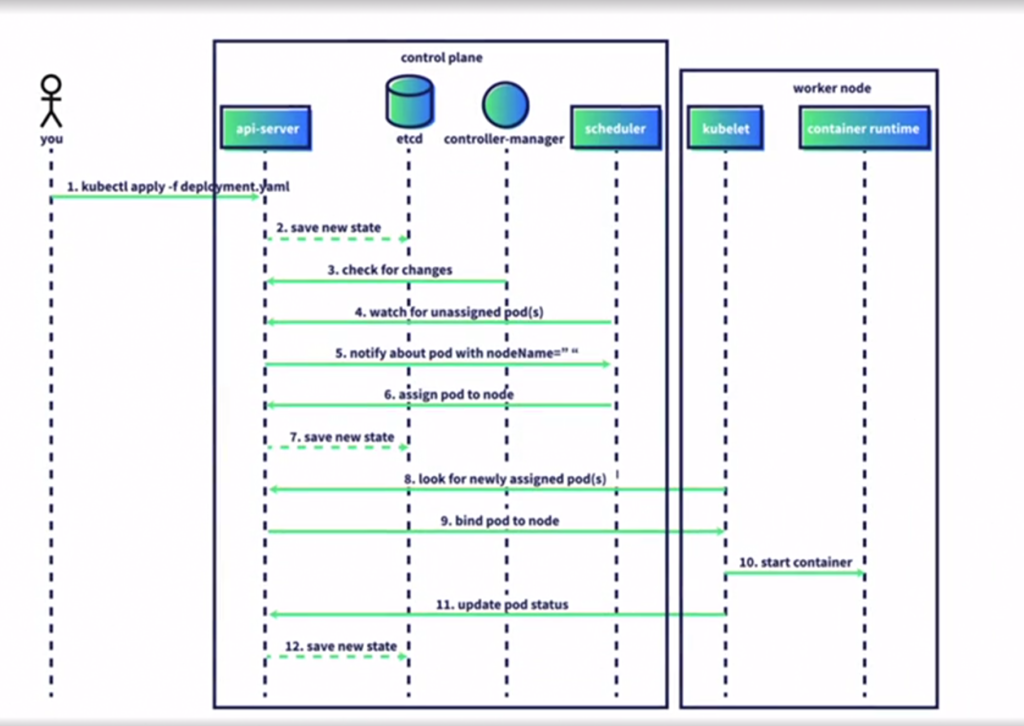
Quello che la CLI fa principalmente è parlare con API Server che è in ascolto nel Control Plane e quando l’amministratore fa delle richieste tramite CLI, quello che succede dietro le quinte è che quel comando viene convertito nella chiamata API appropriata e mandato all’API Server che ha il compito di rispondere.
Un esempio è:
kubectl get pods
Convertito in:
curl http://localhost:8001/api/v1/pods
{
"kind": "PodList",
"apiVersion": "v1",
"metadata" : {
"selfLink": "/api/v1/pods",
"resourceVersion" : "3502280"
},
"items" : [
Per poter utilizzae kubectl per amministrare un K8s cluster bisogna essere autenticati, attenzione che la versione di kubectl deve essere compatibile con l’API service version. La best practice è avere una versione superiore sul cliente rispetto all’api server, o comunque uguale o maggiore all’apiserver.
I comandi più comuni di k8s includono: apply, get, describe e delete.
Apply – applica il contenuto di un certo YAML file
kubectl apply -f /percorso/file/file.yaml
Get – fornisce informazione di base riguardanti un certo oggetto
kubectl get pod <nome pod>
Describe – fornisce informazioni più dettagliate riguardanti un certo oggetto
kubectl describe pod <nome pod>
Delete – cancella un oggetto
kubectl delete pod <nome pod>
kubectl get nodes -o wide
kubectl get pods –all-namespaces
Muoversi tra i diversi namespace
Il namespace può essere associato al concetto di resource pool di vSphere, dove è possibile assegnare limiti, risorse e permessi a determinati gruppi di utenti.
kubectl get namespace – fornisce la lista dei namespace disponibili
kubectl config set-context <context> –namespace=<namespace> –
Se si ha accesso a diversi namespaces, per poter definire dove andare a creare un certo oggetto si usa il comando poco sopra per definire il default namespace da utilizzare.
Troubleshooting Kubernetes
Per verificare gli event log di un cluster si può usare il comando: kubectl get events
(by default gli eventi e la loro history sono archiviati per un ora)
kubectl get pods -o wide – ” -o wide” utile per verificare degli oggetti con colonne aggiuntive che potrebbero fornire informazioni utili in fase di controllo e risoluzione di eventuali problemi
kubectl describe pod “podname” – comando che è in grado di dare informazioni dettagliate riguardanti un oggetto, anche questo utile per fare troubleshooting
kubectl logs “nome oggetto” – mostra i log di un determinato container “se è l’unico container nel pod”
kubectl logs -c “container name” – mostra i log di un detarminato container parte di un pod con più di un container
Creare oggetti in Kubernetes
kubectl ha due modalità di utilizzo che sono la modalità dichiarativa (che è anche la consigliata) ma anche la modalità imperativa.
La dichiarativa utilizza un nuovo oggetto utilizzando un file come ad esempio il comando qui sotto:
kubectl apply -f “file – directory -url”
La modalità imperativa invece:
kubectl create – crea una nuova risorsa da un file
kubectl replace – aggiorna un risorsa esistente da un file
kubectl edit – aggiorna una risorsa esistente usando un default editor
kubectl patch – aggiorna una risorsa esistente combinando un code snippet
Stati dei POD
Pending: il pod è accettato dal sistema ma una o più immagini non sono state create. Include il tempo necessario a schedulare i pod e il tempo necessario a scaricare l’immagine tramite la rete.
Running: il pod è stato associato al relativo nodo, e tutti i container sono stati creati
Succeeded: tutti i container nel pod sono stati terminati con successo e non sono stati riavviati.
Failed: tutti i container nel pod sono stati terminati. Almeno uno dei container è stato terminato per un problema
Unknow: lo stato dei pod non può essere verificato, potrebbe esserci un problema di comunicazione tra l’host e il pod.
Autocompletamento in bash:
echo ‘source <(kubectl completion bash)’ >>~/.bashrc
https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/
Kubernetes Objects
– Pods
– Replicasets
– Deployments
– Services
– Namespaces
– Labels
Gli oggetti sopra possono essere definiti tramite i cosidetti “Manifest”, che dichiareranno il “desired state” del relativo oggetto.
I Manifest hanno le seguenti proprietà:
– sono in formato YAML e quindi necessitano di una precisa formattazione
– hanno una configurazione dichiarativa
– hanno all’interno la versione delle API Primitives usata da Kubernetes per la creazione dell’oggetto
PODS
è la più piccola unita di lavoro che Kubernetes gestisce ed può essere formato da uno o più containers. (i containers all’interno di un pod vivono e muoiono insieme)
Esempio manifest file
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-xxxx-abcdz
lables:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80Il pod è creato da kubernetes per un preciso scopo ovvero quello di avviare i container. Il container è la ragione per cui il POD come oggetto esiste.
immagine disegno pod-container
All’interno di un pod come detto precedentemente è possibile avere anche più di un container, in questo caso i container sono avviati sullo stesso worker node, sono in grado di comunicare tra di loro tramite “localhost” e possono condividere anche un volume come risorsa.
Questo è il caso per esempio dei cosidetti “Sidecar Container” il cui compito solitamente è quello di raccogliere log, metriche dei pods per poi inviarle ad un sistema di logging o monitoring.
sidecar container immagine
I pod sono sempre associati ad un solo worker node, non vi è la possibilità di distribuirli tra più worker node, come vengono distribuiti i pod su i worker node è parte delle responsabilità del servizio di scheduler che amministra e verifica dove piazzare i pod.
REPLICASET
Questo oggetto dichiara il numero di replica che vogliamo ottenere per un determinato pod.
La replicaset crea e mantiene le copie del pod, le repliche del pod che possono essere ospitate sullo stesso k8s node ma anche su nodi diversi.
DEPLOYMENTS
è l’oggetto più comunemente usato, fornisce la possibilità di fare aggiornamenti creando ReplicaSets e distruggendo ReplicaSets automaticamente.
Permette quindi di abilitare una nuova versione di un immagine senza disservizio.
kubectl get replicasets
SERVICES
Un servizio descrive come i pods possono essere raggiunti e come possono comunicare tra loro e con la rete esterna. Un servizio essenzialmente espone un deployment con un singolo indirizzo IP.
Un esempio di un file manifest per un service potrebbe essere il seguente:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-service
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- port: 80
protocol: TCP
targetPort: 80Come potete notare il tipo di servizio viene definito con il valore “Type” e per associarlo a un determinato pod o gruppo di pod è l’utilizzo del termine “selector“.
Gli altri diversi tipi di servizio di LoadBalancing possono essere: NodePort, ClusterIP e LoadBalancer.
La differenza sostaziale è che il servizio load balancer espone i pods con un indirizzo ip esternamente ( può essere una soluzione esterna a k8s) mentre il clusterip viene usato solo per il traffico interno.
kubectl get services
NAMESPACES
L’oggetto namespace fornisce un costrutto con cui è possibile assegnare un certo quantitativo di risorse ed al tempo stesso specificarne le autorizzazioni. (Una specie di Resource Pool) Il namespace può essere distribuito tra diversi nodi k8s che fanno parte di un cluster ma non può essere distribuito tra più cluster k8s.
– Supporta l’accesso multi utente
– Le risorse assegnate e usate sono controllate dalle “resource quotas”
kubectl get namespaces
LABELS
I labels sono un etichetta che viene attacata ai pod per descriverne gli attributi. L’utilizzo è quello di utilizzare queste labels per poter selezione e controllare meglio i pod, la scelta è libera ma ovviamente la best practice è quella di non creare labels che sono una somma di più attributi (esempio, “app: myblog-frontend), ma utilizzare invece più labels per descriverne gli attributi. (esempio, app: myblog, tier: frontend)
kubectl get labels
Built-in Deployment Strategies
Rolling Update:
– é il metodo utilizzato di default se non specificato diversamente nel deployment
– Viene creato un nuovo ReplicaSet che viene esteso (scaled-up) mentre l’oldReplicaSet viene diminuto (scaled-down)
A procedura ultimata l’oldReplicaSet viene comunque mantenuto (vuoto senza pod). Viene fatto con il preciso scopo di poter permettere un rollback veloce alla versione precedente se qualcosa non funziona come desiderato.
Recreate deployment (outage/downtime dell’applicazione):
– Rimuove tutti i pod esistenti nei ReplicaSet prima
– Crea nuovi pods nel ReplicaSet
In questo caso la procedura porta a 0 l’oldReplicaSet (causando di fatto il down dell’applicazione) dopodichè viene creato il nuovo replicaset e vengono instaziati i pod secondo quanto desiderato/configurato nel deployment.
Canary
- Creare un nuovo pod per una parte del traffico
- Due Deployments con un particolare utilizzo di labels tra loro per permettere di poterli separare (esempio il campo “track” nel manifest file) e inviare così parte del traffico al pod con la nuova versione.
Blue/Green
- Utilizza lo stesso metodo precedente ma qui sarà i due deployments paralleli con lo stesso numero di pods.
- viene utilizzato un label per gestirli e fare gli switch tra versioni
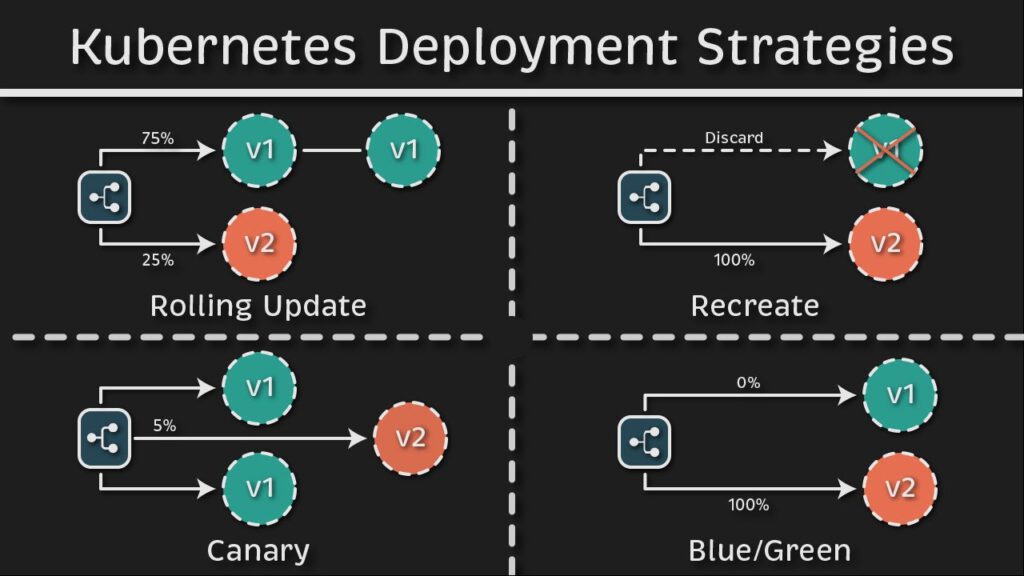
Spiegato molto bene in questo articolo:
https://blog.devops.dev/kubernetes-deployment-strategies-part-2-ec2290717fcb
kubectl rollout | pause | resume | deployment “name”
Probes
I probe sono un sistema di diagnostica eseguito periodicamente dal kubelet su un container. Si possono configurare dei probe “liveness” e “readiness”:
Liveness
- Identifica quando il container è in stato running
- quando c’è un failure, il container viene riavviato in base alla policy
Readiness
- Identifica quando il container è pronto per poter gestire le richieste o traffico
- quando c’è un failure, il pod viene rimosso dal servizio in modo tale che non riceva richieste o traffico
Per eseguire questa diagnostica con i Probe il servizio kubelet richiama i gli “handler” implementati dal container. Ce ne sono di diverso tipo:
Exec
- Avvia un comando all’interno del container
- Quando il return command è 0 significa “Success”
TCPSocket
- Fa un controllo usando il protocollo TCP
- Verifica che una certa porta sia aperta e accetti connessioni
HTTPGet
- Esegue un HTTP Get verso un certo URL
- Se riceve una qualsiasi 2xx o 3xx HTTP Response è “Success”
I probes possono essere configurati anche con parametri di sensibilità che includono initialDelaySecons, periodSecons, timeoutSeconds, successThreshold e failureThreshold.
Network in Kubernetes
CNI – o Container Network interface è indispensabile quando si va ad installare kubernetes è quello di installare una soluzione per il network.
Alcune delle soluzioni più popolari sono, Kubenet, Flannel/Calico, Wave Net.
Con VMware Tanzu alcune soluzioni sono: Contour, NSX-T Data Center, NSX ALB, Antera, Project Calico e HAProxy.
Da sapere che ai componenti undelying di Kubernetes non interessa in realtà quale soluzione avete scelto come CNI.
Antrea
E’ una soluzione opensource disegnata specificamente per Kubernetes, utilizza infatti la Kubernetes controller architecture, Api server e le custom resource definition per costruire il control plane ed estendere le Kubernetes API.
Utilizza un estensione di kubernetes e gli Open vSwitch data plane per fornire servizi network con benifici sulle perfromance, portabilità, operazioni, flessibilità ed estensibilità.
Il compito del CNI è la connettività tra i diversi pod, utilizzando un indirizzo ip che è ruotabile dovunque all’interno del cluster. Come visto precedentemente i pods possono essere anche raggiunti utilizzando i “services” (clusterip, nodeport e loadbalancer), utilizzati per poter bilanciare il traffico verso un particolare gruppo di pods.
Ingress
In kubernetes l’ingress è un metodo per ruotare il traffico che arriva dall’esterno ai pods.
– Lavora a L7
– Fa routing delle richieste in base agli HTTP headers
– Ha diverse funzionalità in base al tipo di implementazione
– Esistono diversi ingress controller tra cui: contour, NSX-T Data Center, NSX Advanced (AVI), NGINX, Traefik, ALB.
Ingress Controller
Fa parte del control plane, è un pod che è avviato all’interno dei manager node.
Il data plane invece è l’ingress pod che è in realtà il componente che gestisce il traffico secondo le regole o policy configurate all’interno dell’ingress object sottoforma di YAML file.
Service Discovery
Permette all’applicazione di essere registrata come servizio con nome (DNS) in modo tale che i pod relativi siano raggiungibili e bilanciabili tra loro. In questo modo anche se i pod sono creati e distrutti on demand, il traffico frontend e backup continua a funzionare senza problemi.
CSI – Container Storage Interface
Fornisce le API tra Kubernetes e gli storage providers:
– fornendo uno standard comune per esporre il sistema storage a kubernetes
– i provider di terze parti creano i CSI plug-in con cui possono abilitare l’utilizzo di funzionalità e nuovi sistemi storage
Normalmente i volumi montati ad un pod vengono anche chaiamti stateless, poichè esistono finchè il pod esiste, ma quando quest’ultimo viene distrutto e ricreato quello che si ottiene è un nuovo spazio utilizzabile. Perciò in alcuni casi è necessario che questi dati siano persistenti, con l’utilizzo del CSI è possibile infatti collegare ai pod uno storage che è permanente anche se il pod viene rischedulato, distrutto o ricreato, sullo stesso o su altri worker del cluster kubernetes. E’ questo il caso del Persistent Storage.
Persistent Storage
In alcuni casi quindi vi è la necessità di dover avere questo tipo di volumi montati ai pod
– I container per loro natura sono effimeri. I dati devono essere persistenti e devono poter sopravvivere al riavvio o alla rischedulazione di un container.
– Quando avviene una rischedulazione di un container, l’oggetto potrebbe essere distrutto su un host e ricreato su un altro host. In questo caso lo storage deve essere disponibile sul nuovo host in maniera tale che il container possa ripartire in maniera corretta.
– L’applicazione non gestisce il volume o i dati. L’infrastruttura sottostante deve gestire la complessita di dover smontare e rimontare il volume.
– Alcune applicazioni hanno un forte richiesta identitaria, il disco e il container vengono schedulati con un certo ID che deve rimanere lo stesso anche quando viene rischedulato.
Persistent Volume – PV
è una allocazione di risorse storage che possono essere usate da un applicazione dentro il container.
Questo volume è gestito dagli amministratori storage e ha le seguenti caratteristiche:
– astrazione dallo storage provider utilizzando il CSI
– è simile ad un normale volume ma ha un life cycle che è indipendente dal pod che utilizza il PV
– le risorse storage sono fornite al cluster da un amministratore
– può essere provisionato in maniera dinamica o statica a seconda dei casi (comunemente viene fatto dinamicamente per una questione di gestione semplificata)
Persistent Volume Claim – PVC
è utilizzato per potere utilizzare il PV creato precedentemente:
– richiede dettagli specifici allo storage
– agisce ricercando il PV che ha le specifiche richieste
– il PVC consuma le risorse del PV in una maniera analoga a come un po consuma le risorse di un nodo, richiedendo però uno spazio specifico e diversi metodi di accesso (read-write once, read-only many times)
– quando PVC viene cancellato, i dati sono cancellati by default e questo comportamento è controllato dalla reclaim policy
Storage Classes
Sono un costrutto di Kubernetes che sono l’equivalente delle storage policy di vsphere
– definiscono e assegnano delle storare policy a un namespace
– le vSphere storage policy sono tradotte in Kubernetes storage classes
– gli sviluppatore possono accedere a tutte le storage policy assegnate stottoforma di storage classes
– normalmente gli svilupatori non gestiscono le storage classes
Una storage class permette all’amministratore di descrivere la classe dello storage che è in grado di offrire.
Ogni storage class continere un campo provisioner, parametri, e la reclaimPolicy che viene usata quando un volume persistente “PV” appartiente ad una class che deve dinamicamente fare provisioning. (dynamically provisioned)
Differenti classes possono essere usate per costruire una sorta di Quality of service, policy di backup o possono essere definite dall’amministratore del cluster.
Un esempio qui sotto di un manifest di una storage class basata su una policy di un datastore vSAN:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: thin
hostFailureToTolerate: "1"
datastore: vsanDatastore
reclaimPolicy: RetainL’utilizzo del persistent storage prevede l’utilizzo quindi di diversi oggetti che possono essere modificati o creati. L’immagine qui sotto riassume la relazione degli oggetti quali storage, PV, PVC e POD.

Parametri StorageClass che abbiamo visto sopra:
– diskformat: thin, zeroedthick or eagerzeroedthick
– datastore (optional): nome del VMFS o vSAN Datastore
– storagePolicyName (optional): Nome della SPBM policy da applicare
Si possono inoltre aggiungere ulteriori parametri se si tratta di vSAN come per esempio: cachereservation, diskStripes, forceProvisoning, hostFailuresToTolerate, iopsLimits e objectSpaceReservation.
E’ possibile inoltre puntare direttamente a una Storage Policy di vSphere invece che specificare ogni parametro dentro la storage class.
Persistent Volume Claim
kind: PersistenVolumeClaim
apiVersion: v1
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 5Gi
storageClassName: slowPVC in un POD
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: my-mysql
image: mysql:5.7
volumeMounts:
- mountPath: "/var/lib/mysql"
name: mysql-pd
volumes:
- name: mysql-pd
persistentVolumeClaim:
claimName: mysql-pvcStatefulSets
Viene utilizzato quando un deployment deve essere persistente ed in questo caso ogni replica usata nell’ambiente deve avere il proprio persistent volume.
Gli StatefulSets hanno le seguenti caratteristiche:
– stabile, unico identificativo pod e nome dns
– storage persistente, un PV per PVC
– deployment controllato dei pod
(https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/)
ConfigMaps
E’ un oggetto di Kubernetes usato per memorizzare i dati non riservati in un sistema di coppie chiavi-valore. I pods possono utilizzare le ConfigMaps come variabili d’ambiente, argomenti per le linea di comando o come file di configurazione.
Secrets
Utilizzato per salvare dati sensibili come password, token o chiavi:
– il secret è solitamente in formato Base64-encoded
– come i configmaps, i secrets sono esposti al pod sottoforma di variabile di ambiente e montati come volumi
– alcuni prodotti di terze parti forniscono alcune funzionalità avanzate come username, password e gestione chiavi
(https://kubernetes.io/docs/concepts/configuration/secret/)
Jobs
Utilizzati per uno specifico bisongo in cui ci sia bisogno di avviare un azione una volta sola (per esempio, inizializzare un servizio o simili)
Le caratteristiche del job sono:
– viene avviato fino al completamento
– basato su pod o container
– riprova continuamente by default se c’è un errore o un failure (il valore di exit non è 0)
Una volta completato il suo scopo il job rimane, in maniera tale da permetter di poter verificare i logs, output e altre informazioni. L’amministratore in questo caso può implementare o detarminare delle regole di clean-up.
Esempio di un manifest file per un Job (https://kubernetes.io/docs/concepts/workloads/controllers/job/)
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
CronJob
Utilizzato in questo caso per eseguire un comando schedulato (esempio: un job che deve essere eseguito alle 11 PM)
Può essere schedulato per essere eseguito una volta sola oppure ri-eseguito ad un orario specifico.
Le caratteristiche del cronjob sono:
– ad ogni esecuzione un nuovo job con relative risorse sono create
– by default, tre job eseguiti con successo sono tenuti in memoria, e un job fallito. (se viene eseguito più frequentemente ovviamente vengono mantenuti i job più recenti e cancellati i più vecchi)
Un esempio di CronJob (https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/)
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
DaemonSets
Il daemonsets si assicura che tutti i nodi abbiano una copia del pod avviata:
– quando un nodo viene aggiunto nel cluster i pods sono automaticamente aggiunti a nuovo nodo
– quando viene rimosso un nodo dal cluster, i pod sono cacellati
– solitamente vengono utilizzati per soluzioni o funzioni di amministrazione del cluster
Un esempio sono i Cluster-wide logging agents o Cluster-wide monitoring agents
Security in Kubernetes
Network Policy
La network policy non è altro che una regola firewall che permette la comunicazione tra gruppi di pod.
Vengono utilizzati i labels per la selezione dei pods e per definire le regole che permettono il traffico tra loro.
Di base i pod non sono isolati tra loro, infatti tutto il traffico è accettato da qualsiasi sorgente.
I pod diventano isolati in una delle seguenti situazioni:
– quando viene definita una NetworkPolicy che li seleziona in un namespace
– quando un pod rifiuta le connessioni che non sono permesse in maniera esplicità da una networkpolicy
– quando gli altri pods nel namespace che non sono selezionati dalla networkpolicy continua ad accettare tutto il traffico
Security Context
Il security context definisce i privilegi e il controllo degli accessi di un pod o un container.
La sezione PodSpec definisce i privilegi di un container, permettendo di a tutti i container di averi gli stessi privilegi oppure di avere anche privilegi diversi tra i container parte di un pod.
Gli amministratori del cluster possono forzare delle restrizioni utilizzando le policies.
(https://kubernetes.io/docs/tasks/configure-pod-container/security-context/)
Un esempio preso direttamente dalla documentazione kubernetes:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: busybox:1.28
command: [ "sh", "-c", "sleep 1h" ]
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: false
Api Access Control
Controllare l’accesso degli utenti non è possibile tramite kubernetes direttamente.
Un servizio di identità esterno deve essere usato per poter generare dei token che possano permettere all’utente di poter comunicare con il Kubernetes API server.
Kuberenets supporta OpenID Connect (OIDC) tokens per identificare gli utentei che vogliono accedere al cluster.
(VMware Tanzu come soluzione per gestire kubernetes per esempio permette l’autenticazione degli utenti tramite il PSO SSO domain/vSphere, LDAP e OIDC)
Metodi di autenticazione includoono certificati, tokens o autenticazioni esterne.
I client certificate solitamente vengono usati per i componenti del cluster.
I tokens sono usati per service account, generati automaticamente quando un service account viene creato e viene montato all’interno dei pods in /var/run/secrets/kubernetes.io/serviceaccount
Autenticazione esterna viene usata per gli utenti che infine genera un OIDC token per permettere l’accesso
RBAC
Role Based Access Management si riferisce all’autorizazzione che usa Kubernetes per definire “CHI” (utente, gruppo o service account), a “DOVE” ha accesso e “QUALE” accesso ha (read,write, admin, auditor).
In questo caso viene usato il ROLE, che è una collazione di permission, può essere standalone e quindi legato ad un oggetto oppure può essere specifico di un namespace.
(https://kubernetes.io/docs/reference/access-authn-authz/rbac/)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]Il clusterRole è invece un ruolo che è distribuito su tutto il cluster e quindi è possibile riutilizzarlo globalmente all’interno di tutto il cluster k8s.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
#
# at the HTTP level, the name of the resource for accessing Secret
# objects is "secrets"
resources: ["secrets"]
verbs: ["get", "watch", "list"]Con il RoleBinding andiamo a combinare il CHI e DOVE come nell’esempio qui sotto.
(https://kubernetes.io/docs/reference/access-authn-authz/rbac/#rolebinding-example)
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows "jane" to read pods in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# You can specify more than one "subject"
- kind: User
name: jane # "name" is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role #this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.ioIl ClusterRoleBinding ha le stesse specifiche del RoleBinding con la differenza sostanziale che il ruolo assegnato è global all’interno del cluster e di tutti i namespace parte del cluster.
(https://kubernetes.io/docs/reference/access-authn-authz/rbac/#rolebinding-example)
apiVersion: rbac.authorization.k8s.io/v1
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.ioKubernetes ha dei ruoli che sono già presenti by default e sono i seguenti:
- Cluster-Admin: super user access per fare qualsiasi azione su tutte le risorse. Con il ClusterRoleBinding da permessi totatli su tutte le risorse del cluster e tutti i namespace.
- admin: accesso admin all’interno di un namespace, permette di creare ruoli e rolebinding ma non permette ri accedere a resource quota o al namespace direttamente.
- edit: permette read&write nella maggior parte degli oggetti di un namespace.
- view: accesso read-only per vedere la stragrande maggioranza degli oggetti in un namespace. Non è possibile vedere i rolebindings e i secrets.
Esempio RBAC #1
Giuseppe ha bisogno di un ruolo read-only per il clusterkind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: my-global-access
subjects:
- kind: User
name: Giuseppe
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.ioEsempio RBAC #2
Giuseppe deve avere accesso come edit ad un particolare namespace che si chiama “prova”
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: my-team-access
namespace: prova
subjects:
- kind: User
name: Giuseppe
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.ioLogging
Kubernetes ha diversi log che possono essere usati per fare troubleshooting di aree specifiche nello stack dell’applicazione:
- Container Logs
- Host OS Logs
- Control Plane Logs
- Event messages
I log dei container sono normalmente scritti nel file stdout/stderr all’interno del percorso /var/log/containers
kubectl logs “pod name”
kubectl exec -it “pod name” — bash
Ci sono 4 diversi modi per organizzare il logging all’interno di Kubernetes, alcuni più consigliabili altri meno.
Monitoring
Il monitoraggio è fondamentale per capire nel normale ciclo di lavoro cosa è normale e cosa non lo è e da qui determinare cosa fare in caso di determinati eventi che possono generare alert. Il monitoraggio e l’allarmistica permette quindi poi di agire in maniera proattiva o reattiva per sistemare l’eventuale problematica.
All’interno della piattaforma per container di VMware ci sono diversi livelli e diversi tool da utilizare per monitorare per esempio l’infrastruttura, i cluster kubernetes e le applicazioni che sono avviate al loro interno. (infrastruttura per esempio sarà monitorata da vRealize Operation, Kubernetes da Octant e le applicazioni invece da Tanzu Observability)
Octant Link
Kubernetes rilasci

Come è possibile vedere il versioning usa questi tre valori numerici per il suo versioning che consiste appunto in major, minor e patch.
Le minor release vengo rilasciate ogni 3 mesi circa.
Il progetto kubernetes mantiene le ultime 3 minor release come supporto.
Backup
Quali elementi devono essere sotto backup?
– Resource Definition (Deployments, Services, ConfigMaps eccetera)
– Generated resources (events)
– Persistent volumes
– Secrets
Esistono diverse opzioni per fare il backup:
etcd snapshots/export:
– Richiede accesso al server etcd ed è un processo low level e manuale
– il restore non è controllabile o modificabile
ReShifter:
– richiede accesso al server etcd ma è molto più automatizzato ed ha una sua UI di gestione
Velero:
– Usa i servizi API e non ha dipendenze da etcd
– E’ avviato nel cluster ad intervalli automatici
– L’output è in formato JSON e può essere usato anche per altri scopi
In aggiornamento 10/08/2023